A variation shows a 50% conversion lift in your testing tool, you ship it, and revenue barely moves. The hypothesis wasn't the problem. The test was invalidated before the data had a chance to mean anything.
The threats that actually kill testing programs at an 8-9 figure scale aren't sample sizes or statistical significance. They're subtler: the History Effect, the Novelty Effect, the Instrumentation Effect, Statistical Regression, and the Selection Effect. At your scale, bad test data isn't just wasted budget; it's compounding wrong decisions across thousands of transactions per month.
1. The History Effect
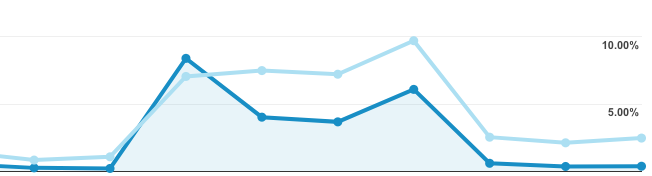
An external event skews your test data, and the traffic spike that appears to be a signal is actually noise.
If you run a test while an influencer campaign is live, you'll end up pulling in visitors with different intent, context, and behavior than your baseline audience. If that traffic is temporary (and it always is), one variation can win purely because it happened to resonate with that atypical cohort.
The variation didn't win. The moment did.
How to keep the History Effect from skewing your tests
If a major traffic event is coming, extend your test by 3-4 weeks so your regular audience makes up a meaningful share of the sample. Don't cancel, compensate.
If you're running paid social during the test, segment that traffic out entirely. Run the test only against Facebook Ads visitors, or exclude them completely. Either way, don't let one channel's audience contaminate the read on another.
Never analyze a test solely inside your testing tool. Intelligems, VWO, and Optimizely show you aggregate performance. Google Analytics shows you what's underneath: audience segments, traffic sources, purchase paths. Use the testing tool to run tests. Use Analytics to understand them.
2. The Instrumentation Effect
Your variation has a bug you don't know about, the variation loses, and you ship the wrong version.
This is one of the most common failure modes for teams new to testing. A variation that doesn't render correctly in Firefox is at a structural disadvantage, not because the design or copy was weaker, but because some users saw a broken page. The test result is fiction.
How to keep the Instrumentation Effect from skewing your tests
QA every variation before launch. Cross-browser, cross-device, every user scenario. Tools like BrowserStack and Browserling cover browser compatibility. Pair them with physical device testing on iPhone, Android, iPad, and various screen sizes. If you don't have the hardware, opendevicelab.com lists community device labs.
Don't use drag-and-drop editors inside your testing tool to build variations. The auto-generated code is messy, frequently incompatible with specific browsers, and prone to mid-test breakage. Get a developer to write clean code. The QA overhead is worth it every time.
If your CRO program is shipping winners that don't replicate in production, request a free proposal. We'll audit your testing infrastructure to identify the validity threats most likely to corrupt your results.
3. The Selection Effect
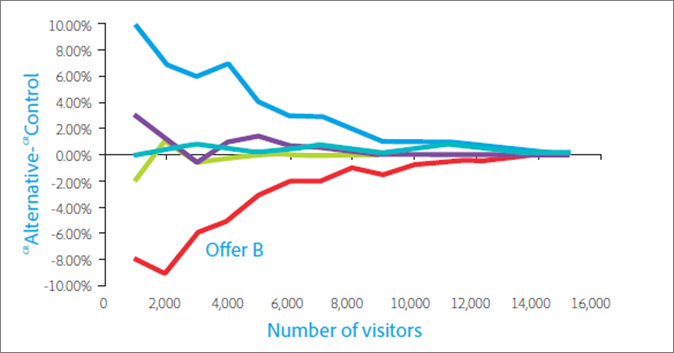
Sending paid traffic to a page that normally gets organic or email traffic, just to hit your sample size faster, is one of the most repeated bad pieces of advice in CRO.
Traffic source determines visitor intent. We had a client run the same landing page for both email and Facebook ad traffic. Of course, traffic sources were tracked and analyzed… and the result? Facebook traffic converted at 6%, and email at 43%. 7x the difference, and this is massively common. Mixing those audiences into a single test produces a number that accurately describes neither group.
How to keep the Selection Effect from skewing your tests
Segment by traffic source in Google Analytics before you call a winner. Your testing tool will show you an average. Averages lie. A variation can "win" overall because it happened to perform better with one traffic source that over-indexed during the test window.
If you don't have enough traffic to test a page with your existing audience, wait. Or test a higher-traffic page first and work downstream. Importing artificial traffic doesn't solve a sample-size problem; it creates a data-quality problem.
4. The Novelty Effect
A dramatically redesigned page gets more engagement, but only temporarily.
Users click around to figure out the new layout. Time on page goes up. Interactions increase. Your testing tool flags a winner. Six weeks later, performance has regressed to baseline or below.
This effect is most dangerous when a large share of your test traffic is returning visitors. New visitors have no baseline to compare against, so they react to the page as-is. Returning visitors are reacting to change, not to quality.
How to keep the Novelty Effect from skewing your tests
For any variation that makes a significant structural change to user flow, run the test for at least 4 weeks. The novelty wears off. The real signal emerges.
After implementation, keep tracking. Session recordings and usability tests will show you whether engagement is genuine or exploratory. Adobe's method for distinguishing the Novelty Effect is clean: segment new vs. returning visitors and compare conversion rates separately.
If the new variation wins with new visitors but not returning ones after four weeks, you likely have a novelty problem, not a winning test.
5. Statistical Regression
In the first few days of any test, results fluctuate wildly, and stopping the test at the first sign of significance is almost certainly stopping during the noisy phase.
That's regression to the mean: extreme early readings normalize over time. If you stop a test the moment it hits statistical significance, you're capturing noise, not signal.
The coin flip analogy from Basecamp data analyst Noah Lorang is the clearest illustration: flip two coins 10 times each, and you might see one land heads every time. Run it to 100 flips, and the difference disappears. Stopping at 10 flips and declaring a weighted coin is exactly what early test termination does.
How to keep Statistical Regression from skewing your tests
Don't end a test the moment your tool declares a winner. Statistical significance is a threshold, not a finish line.
Calculate your required sample size before the test starts using Optimizely's sample size calculator. As a floor, don't end a test with fewer than 100 conversions per variation. And regardless of sample size, run for at least 3-4 weeks to let results normalize and account for weekly traffic cycles.
Your testing tool has a financial incentive to make testing look easy and fast. Don't let its "winner" notification make your decisions for you.
The missing piece: interaction effects between tests
Running multiple A/B tests simultaneously on the same page or funnel introduces interaction effects, in which the variations in one test influence the results of another. This is a validity threat that most teams don't account for until it's already corrupted months of data.
If you're testing a new hero section and a new CTA button at the same time on the same page, visitors in the overlap see a combination of both variations. The performance you attribute to either test is partially caused by the other. Neither result is clean.
The fix is either mutual exclusion (ensuring test audiences don't overlap) or sequential testing, where you run one test to conclusion before starting the next on the same page. Tools like Intelligems support mutual exclusion and groups. Use them. Most teams don't.
The missing piece: pre-test baseline integrity
Before any test launches, your baseline conversion rate needs to be stable. If your control page is mid-redesign, experiencing a tracking bug, or was recently changed, the "control" you're testing against isn't a real baseline. It's a moving target.
8-9 figure DTC brands scaling rapidly are particularly exposed here. Frequent site changes, new app integrations, and recurring promotional cycles mean the page you're testing today may not be the same page it was two weeks ago.
Run an A/A test first (same page against itself) to confirm your measurement is stable before introducing a variation. If an A/A test shows a "winner," your instrumentation is broken.
If you haven't run an A/A test on your highest-traffic pages in the last 12 months, request a free proposal. We'll assess the integrity of your instrumentation before you ship another test.
Frequently Asked Questions
How do you balance rigorous testing against the velocity you need to compound wins at an 8-9 figure scale?
The trade-off is mostly false. Programs that ship invalid winners aren't moving fast, they're moving wrong, and they're accumulating decisions that don't replicate in production. Real velocity at an 8-9 figure scale comes from running fewer, cleaner tests with full validity discipline rather than running more tests with shortcuts. The brands that compound testing wins fastest are the ones that treat the validity threats above as non-negotiable. For the broader operational discipline that makes this work, see [the A/B Testing Process article].
Which validity threat is most commonly missed at an 8-9 figure scale?
The Selection Effect, by a meaningful margin. At an 8-9 figure scale, traffic comes from multiple paid channels, organic search, email, retargeting, and direct, and most teams analyze test results in aggregate inside the testing tool without segmenting by traffic source. The result is winners that "won" because one over-indexed traffic source happened to convert well during the test window. Segmenting test results by traffic source in Google Analytics before calling a winner is the single highest-impact validity discipline most programs are missing.
How do you handle validity threats when running concurrent tests across multiple pages?
Two operational disciplines matter most. First, use mutual exclusion groups in your testing platform (Intelligems supports this) so no visitor enters multiple overlapping tests simultaneously. Second, document which tests are running on each page in a shared calendar, so cross-team coordination doesn't break down. The interaction effects problem compounds quickly at scale: three concurrent tests across overlapping audiences can produce results where none of the three are reliably attributable. For the deeper treatment of concurrent test management, see [the Shopify A/B Testing article].
When should you re-run a test that previously declared a winner?
When any of these conditions hold: the test ran for less than 3-4 weeks regardless of sample size, the test's win was concentrated in a traffic source that has since shifted significantly, the variation was implemented but didn't produce the expected revenue lift in production, or the page has changed materially since the original test. Re-running tests is operationally expensive, but cheaper than continuing to compound decisions on invalid winners. Most programs underestimate how often re-testing is the right move.
How does the validity threat framework interact with the broader 3Ps methodology?
The 3Ps methodology (Patterns, Perception, Proof) covers the upstream work: research-grounded hypothesis development and brand-strategy filtering before testing. The validity threats above cover the downstream work: ensuring the Proof stage actually produces reliable signal rather than noise dressed up as significance. Both layers are required. Research-grounded tests run with poor validity discipline still produce invalid winners, and rigorous validity discipline applied to ungrounded hypotheses still produces winners that won't replicate in production. For the canonical 3Ps methodology, see [the CRO Audit article].
What's the relationship between testing platform choice and validity discipline?
Less than most operators assume. The platform makes some validity work easier (mutual exclusion groups, segment-level reporting, integration with analytics), but doesn't substitute for the discipline itself. A team with rigorous validity discipline running on Intelligems will produce more reliable results than a team with weak discipline running on an Enterprise testing platform.
What's the most common false positive pattern in 8-9 figure CRO programs?
A variation that wins on overall conversion rate but loses on revenue per visitor or AOV. This pattern is especially common in tests that simplify checkout flow or remove upsell mechanics. CVR lifts because friction is removed, but the friction was filtering out low-intent buyers or generating incremental order value. The fix is making RPV your primary success metric rather than CVR.
How do you handle validity when the business demands faster decisions than testing properly allows?
The honest answer is that you don't shortcut the testing; you reduce the number of decisions that require testing. Not every change to the site warrants an A/B test. Brand strategy decisions, urgent fixes for broken functionality, and changes mandated by compliance requirements should ship without testing. CRO testing exists for decisions where the right answer isn't knowable in advance and where the cost of being wrong justifies the test duration. If the business is demanding faster testing decisions, the problem is usually that too many decisions are routed through the testing program, rather than the testing methodology being too slow.

.jpeg)