Most ecommerce brands are running A/B tests. Very few are getting results from them. They pick a test idea from a blog post or an audit deck, launch it, watch the numbers for a week, call it inconclusive, and move on to the next one. Months go by, dozens of tests pile up, and the conversion rate is roughly where it started.
The problem is almost never the test itself. It's what happened (or didn't happen) before the test was launched. Without a research-backed process, A/B testing is just organized guessing, and guessing doesn't compound. Let's talk about what actually works.
A/B testing as part of a conversion rate optimization (CRO) framework
A/B testing isn't a way to directly increase your conversions, as so many testing tools claim in their marketing. It's a way to validate your conversion optimization hypotheses and determine whether your strategy for increasing your average order value, reducing cart abandonment, or reaching other goals is the right one.
The solution to lackluster A/B test results isn't a tactic, which is what A/B testing is on its own. You need a larger framework to help you decide what to test so your efforts don't go to waste.
Research before testing. Always.
The single biggest difference between brands that get CRO results and brands that don't is whether the research came before the test. The exact same test, say, changing which collection is featured in the homepage hero, can be a coin flip or a 70-80% confidence bet depending on what you did in the two hours before launching it.
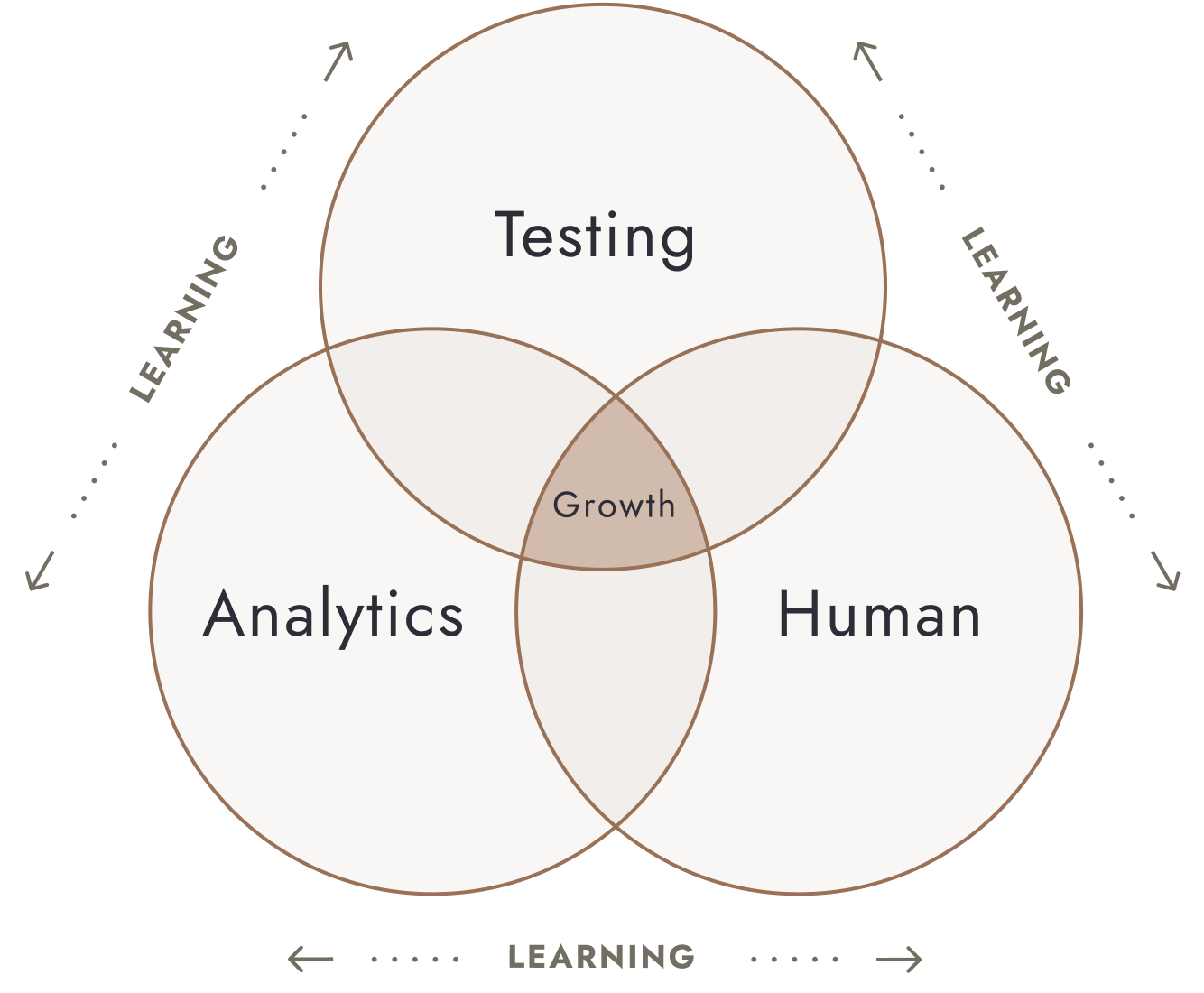
The framework we use internally is called the 3Ps, and it works as a Venn diagram with three overlapping circles.
Patterns: the behavioral, voice, and resistance layer
Behavioral patterns are the quantitative layer: GA4 page paths, heatmaps, scroll maps, and Shopify analytics. What are people clicking on that correlates with a sale? What are they not seeing? Critically, you have to quantify importance here. Is this a majority pattern or a small-percentage outlier? Because the answer changes your entire prioritization.
Voice patterns are the qualitative why. Post-purchase surveys, review mining, and customer interviews. This is where you learn that 60% of your first-time buyers almost didn't purchase because they couldn't tell if the product was right for their skin type, or that your best customers found you through a specific use case you barely mention on-site.
Resistance patterns are the structural friction: broken flows, slow pages, confusing nav. Analytics tell you what and where. Voice tells you why. Resistance tells you what's quietly killing you.
Proof: testing as a research instrument
Every test is both a business decision and a research instrument. The output isn't just a win or a loss. It's a new pattern that feeds back into the next round of research.
This is why we think about testing as cyclical, not sequential. Research feeds testing, testing generates research, and the loop never stops.
Perception: the positioning filter
How is your brand perceived against competitors? What's the narrative needed to anchor your positioning?
This is the filter that prevents you from optimizing conversion mechanics that conflict with your strategic positioning. You can have the highest-converting hero section in your category, but if it makes your premium brand look like a discount play, you've won a battle and lost the war.
Here's the contrarian point most CRO content won't tell you: clients come to us with audit reports stating "this made a million bucks for another brand," and when those same tests get launched, they don't just fail. They become $100K/month losses.
We can't predict test results, and nobody has a crystal ball. But borrowed winners have no research basis for your brand. There's no story behind them. When you do your own research, every test you run has a specific user behavior or pattern that led you to it. That context makes the test more likely to win, and more likely to teach you something useful when it loses.
Use the CRO hierarchy. Don't skip to innovation.
Not all optimizations are equal, and the order you tackle them in determines whether your testing program compounds or stalls. The hierarchy is:
Optimize what's working. High-traffic pages, key conversion points, and the steps most users actually touch. This is where most measurable revenue lives.
Innovate. New layouts, new offers, new funnels, new page types. High-risk, high-reward, but useless if the foundation is broken.
Most brands jump straight to innovation: new PDP redesigns, new funnel experiments. And they wonder why nothing wins. They're trying to layer creative bets on top of leaks they haven't fixed. Even at $100M+, plenty of brands haven't done the foundational work and are skipping ahead.
The same principle applies specifically to landing page optimization. The maturity ladder is: nail the offer, nail the value prop, identify the best landing page format per channel, find the 20% of audience driving 80% of results, make sure every product that needs a landing page has one, and test those pages until they work. Only then, explore personalization. Jumping to personalization before this foundation is in place burns ad spend on tests that lack validity and obscures what's actually driving revenue.
Test fewer, bigger things on higher-traffic pages
The number one reason A/B tests fail isn't bad ideas. There's not enough traffic per variant. Brands with 50K monthly visitors try to run 15 variations on a product page and wonder why none of them reach significance. That's a math problem, not a creative problem.
The solution: fewer tests, bigger swings, on higher-traffic pages. One bold homepage test will teach you more than 10 micro-tests on low-traffic category pages.
This connects directly to test prioritization. The framework is impact multiplied by confidence multiplied by ease. Most teams over-weight ease and end up testing button colors all year. Push for high-impact tests even when they take longer to build.
When A/B/n testing (multiple variants) makes sense and when it doesn't
The rule: if all variants answer the same question, A/B/n is fine. If they answer different questions, run them sequentially.
Good fits for A/B/n: copy tweaks (e.g. "Money back guarantee" vs "Try at home"), position of a new element (shipping info near price vs near CTA), or tactical execution choices. These are variations on the same hypothesis, and you can learn from all of them in a single test.
Bad fits: completely different strategies (video-focused PDP vs long-form storytelling PDP). Those are different hypotheses. Learn from one before designing the next. Also bad for stores under roughly 3,000 orders per month or low-baseline-CVR flows, because the data dilutes and time-to-learning stretches indefinitely.
What's worth testing?
To see results from split testing, you have to be smart about what you choose to experiment on. Some of the highest-impact elements on your website may include the following:
Your website's theme, navigation, and page layout or structure
Your offer, product assortment, bundles, upsells, and cross-sells
The content that lives on your site, including your website copy, calls-to-action, and photos, videos, or interactive elements
The underlying messaging that your website copy and marketing campaigns are based on
But that doesn't mean you can pick one of the above at random, run a test, and expect performance improvements. Prioritization is essential to avoid spinning your wheels and wasting your resources. For instance, you might prioritize test ideas that fall into either of these categories:
They address severe issues that impact a large percentage of potential customers
They would be fairly easy to implement, but have an outsized positive impact
How to set up A/B tests on Shopify sites
Once you've decided what to test first, what next? There are five steps you'll need to take.
1. Develop a rock-solid hypothesis
Again, by this point, you'll have identified a problem area or opportunity worth exploring. Now, you'll need to put some thought into potential solutions.
For example, say your landing page copy isn't quite cutting it, and it's hurting your conversion rate. You've done customer interviews to get a better grip on your target customers' pains, goals, and conversion triggers and to gather voice of customer data. There are a few common threads across the interviews that could make for more effective messaging.
Your hypothesis would be that updated, research-backed messaging will improve conversions.
2. Determine how many variations you can test
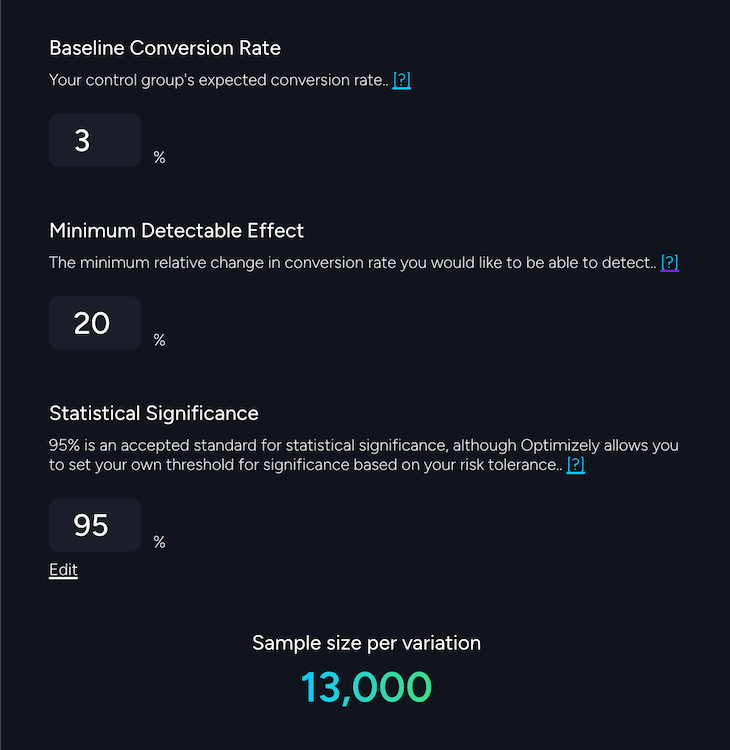
Continuing with our example above, you'll need to figure out if testing all of the potential messaging pillars you've identified is doable. Sample size, which you can figure out using a calculator like Optimizely's, is a key consideration here.
You need enough eyes on each variation to get reliable test results. But you also don't want to be forced to drag out a test for months on end until you can reach the necessary sample sizes for each one.
To illustrate, it wouldn't make much sense for an ecommerce site that only gets about 25,000 unique visitors per month to test four variations of on-site messaging if they needed a sample size of 16,000 per variation. It would take nearly three months to get the 64,000 unique website visitors needed and reach the minimum for each variation.
Not only would that be inefficient but it may also steal away resources needed for other high-priority tests. In such a case, it would be better to start by testing one carefully chosen variation against your control. This would allow you to reach statistical significance in just over four weeks, which is the typical timeframe for tests.
3. Set up test variations
It's at this point that many people pick a testing tool (likeIntelligems, Convert, or VWO), do the quick setup steps, use the provided visual editors or no-code features to create their variations, and hope for the best. But, especially if you plan to run complex tests and do a lot of them, this can get you into trouble.
Code generated automatically by visual editors can cause browser incompatibility or bugs that degrade the performance of one or more variations. This validity threat, called the Instrumentation Effect, means skewed A/B test results (e.g., false positives).
With the exception of the simplest tests, it's best to have developers code your variations and test them thoroughly for cross-browser and cross-device compatibility. We never skip this step at SplitBase; it's been instrumental in ensuring experiments launch bug-free and in getting us accurate insights as quickly as possible.
4. Let your test run
Don't rush to end a test just because you've reached your sample size targets and your A/B testing tool says you've got statistically significant results. Most tests should last at least three to four weeks to allow time for regression to stop. In other words, to allow time for large fluctuations after a test is launched to settle down.
There's no hard and fast rule on when to end a test, but we recommend waiting until you hit all of the following targets:
At least 100 conversions per variation
Required sample size reached
Three to four full weeks of testing
At least 95% statistical significance
You can then compare key metrics across the different versions of your page. Just be sure you choose metrics that tie directly to business goals like increasing revenue rather than focusing on less reliable or valuable metrics like click-through rate (CTR).
Expect a 20-40% win rate. Be suspicious if it's higher.
The industry-standard win rate for A/B tests is roughly 1 in 7, or about 14%. That's the baseline. A mature CRO program with research-driven hypotheses runs 20-40%.
But here's the nuance most people miss: a win rate that's too high is a warning sign. If you're hitting 60%+, you're probably not taking enough risk. You're testing things that should have just been implemented: bug fixes, obvious UX problems, things you already had enough confidence to ship. You're using the testing program as a validation tool instead of a learning tool.
Even a strong data-driven testing program will have a variable win rate, depending on the website's maturity and the experimentation program. Mature websites mean harder-to-find wins, but each win matters more. New programs mean more low-hanging fruit and higher early win rates.
The reframe: tests aren't about winning. They're about learning. A losing test that teaches you something about your customer is more valuable than a winning test that nudges revenue 2% without explaining why.
The process maturity gap: where most $20M brands die
The biggest gap between $20M and $80M brands in CRO has nothing to do with budget, tools, or team size. It's patience with the process.
At $20M, brands are growing fast, and things are moving. There's still impatience baked into how website decisions get made. Tests get launched, but results get checked every single day. People wonder if the test should be stopped early. Gut-feel calls override the data because "it seems like common sense." There's an unconscious need to control the outcome instead of letting data drive it.
At $80M, brands are radically more process-focused. A test runs for two weeks. They follow the plan. They don't let distractions cloud the way. They've developed a clear internal routine for when to rely on data versus gut feeling, because both have a place, but most teams don't know when each applies.
The muscle to build: knowing the difference between data leads and gut leads, and having the discipline to act accordingly. Most $20M brands haven't built it yet. The brands that develop it earlier are the ones that scale faster.
And there's a related tension worth naming: speed vs rigor. Running 50 half-baked tests teaches you nothing. Running 12 well-researched tests in a quarter, each backed by data and a clear hypothesis, that's how you actually learn.
Fix the ideation bottleneck, not just the results bottleneck
The common narrative is that brand teams kill winning variants: they see results they don't like and pull the test. That happens. But the bigger, more hidden problem happens earlier.
Brand teams kill test ideas before they ever run.
The real friction isn't at the results stage. It's at the ideation stage. Not every idea should be tested, and some filtering is appropriate. But when brand gatekeeping prevents high-potential ideas from being validated at all, you lose revenue you can never measure. There's no data trail for the test that was never run. No retrospective. No lesson learned. The revenue just doesn't show up, and no one knows why.
The fix is a process that evaluates high-potential ideas against research, not gatekeeping them by opinion. If an idea has behavioral data, voice data, and a clear hypothesis behind it, brand teams need a higher bar to kill it than "I don't like the way it looks." Otherwise, the entire research-to-testing loop breaks at the most expensive point: before it even starts.
To win more consistently, rely on a research-driven A/B testing process
Split testing is deceptively simple; there are many A/B testing mistakes you can make if you're not careful. This is why it's so important to have and stick to a proven A/B testing process (and to enlist professional help if you don't have the comfort level or resources to execute it properly).
Mistakes like guessing which test ideas to pursue and failing to do quality assurance on tests can cost you big time. Low test quality will mean that your efforts won't make a meaningful impact and clue you in on what works and what doesn't. Plus, you'll waste time and money in the process.
On the flip side, when you combine the best of your qualitative and quantitative insights to generate solid, data-driven hypotheses, you'll see a higher success rate from your A/B tests. Fashion retailer Haute Hijab's experience is just one of many proofs that this process works. Through four rounds of A/B tests, followed by analyses and diligent documentation of learnings, the brand removed assumptions from its product detail page redesign. As a result, site conversions increased by 26.8%.
To chat in more detail about how to implement proper optimization methodology and what results you can expect from doing so, get in touch. Our team will be happy to put together a free proposal for you and answer any questions you have.
Frequently asked questions about A/B testing for ecommerce
How long should I run an A/B test before ending it?
Most A/B tests should run for at least three to four full weeks, regardless of what your testing tool reports. We recommend waiting until you hit at least 100 conversions per variation, your required sample size, and 95% statistical significance. Stopping early because results "look good" after a few days is one of the most common mistakes, because those early numbers are volatile and settling down takes time.
What's a realistic A/B test win rate?
The industry standard is roughly 1 in 7 tests, or about 14%. A mature, research-driven CRO program typically wins 20-40% of tests. If your win rate is consistently above 60%, that's actually a warning sign. It usually means you're testing things that should have just been shipped (bug fixes, obvious UX problems) rather than taking the kinds of risks that produce real learning and bigger lifts.
Why do "best practice" A/B tests from other brands fail when I try them?
Because they were built on someone else's research for someone else's audience. A test that made a million dollars for another brand had specific user behavior and customer data behind it. When you copy the execution without the underlying research, it's a coin flip at best. We've seen "proven winners" from audit decks turn into $100K/month losses when launched without a research basis. Every test needs a specific pattern from your own data that led you to it.
What should I A/B test first on my Shopify store?
Start with the CRO hierarchy: fix what's broken first (bugs, page speed, broken flows), then optimize what's already working (high-traffic pages, key conversion points), then innovate with new layouts or offers. Most brands skip straight to innovation and wonder why nothing wins. For test ideation, we run three parallel analyses: GA4 page-path data segmented by paid/organic and device, Shopify analytics cross-referencing first-purchase products with LTV, and heatmap analysis focused on revenue per click, not just clicks.
What's the difference between A/B testing and multivariate testing?
A/B testing compares two (or a few) distinct versions of a page against each other. Multivariate testing tests multiple elements simultaneously to see which combination performs best. The catch is that multivariate testing requires significantly more traffic to reach significance, because you're splitting visitors across many more combinations. For most DTC brands, focused A/B tests with clear, research-backed hypotheses are a better use of resources. Multivariate testing makes sense only when you have very high traffic and want to fine-tune elements you've already validated.
How do I know if my CRO program is mature enough?
Look at process discipline, not tools or budget. If your team checks test results daily, stops tests early based on gut feelings, or launches experiments without a documented hypothesis, you're still in early maturity. Mature programs run tests for the planned duration, follow a structured research-to-hypothesis-to-test workflow, document learnings from both wins and losses, and evaluate test ideas against data rather than gatekeeping by opinion. The jump from $20M to $80M in CRO performance is almost entirely about building this discipline.